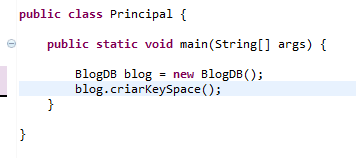
O post dessa semana será diferente, em vez de dar exemplos de uso, casos de sucesso ou até mesmo de discutir sobre implementações, vamos chamar a atenção para uma conferência anual chamada NoSQl Matters que, como pode ser inferido do próprio nome, trata de assuntos referentes ao NoSQL, principalmente quanto ao seu uso, importância e apostas e previsões para o futuro.
 |
| Fonte: http://2015.nosql-matters.org/par/wp-content/uploads/2014/10/nosqlmatters-gro%C3%9F.png |
A edição de 2015 será em Paris, na França, nos dias 26 e 27 de Fevereiro, existem 3 opções de ingressos para o evento, precificados conforme disposição de conteúdo para cada, os preços e disponibilidades de ingresso podem ser consultados aqui.
O evento é direcionado para profissionais da área e estudantes que queiram obter mais conhecimento acerca do NoSQL, diversas palestras serão ministradas, a agenda pode ser conferida aqui. Esta será a quarta edição do encontro, abaixo segue link para edições anteriores, onde estão disponíveis palestras e arquivos de mídia apresentados e discutidos nos eventos:
- NoSQL Matters 2012 - Barcelona, Espanha;
- NoSQL Matters 2013 - Cologne, Alemanha;
- NoSQL Matters 2014 (Setembro) - Dublin, Irlanda;
- NoSQL Matters 2014 (Novembro) - Barcelona, Espanha;
 |
| Fonte: https://s3.amazonaws.com/lanyrd-image-uploads/cropped-profile-photos/e3a312ba79baec59faa9e4b354d7a7823dfd640c.jpeg |
O evento próximo contará com a presença de diversos palestrantes
de empresas bastante conhecidas como : Google, Amazon, Red Hat,
Microsoft entre outras.A ideia central desse post é mostrar que o NoSQL está ativo e possui muitos interessados em seu crescimento e constante melhoria, parece ser algo que realmente veio para ficar, dadas suas diversas contribuições a diversos serviços e empresas, como fora ilustrado previamente neste blog.
Site oficial do evento NoSql Matters 2015. Disponível em <http://2015.nosql-matters.org>. Acesso em 27/01/2015.