O Pinterest é uma famosa rede social de compartilhamento de fotos, afiliado ao Twitter e Facebook, cresceu muito nos últimos anos, possui aplicativos para ios e também para Android. Apenas no ano de 2012 a empresa cresceu mais do que 1047% no número de usuários e postagens que acessaram o serviço via browser em seus computadores pessoais, já no meio mobile o crescimento foi ainda maior, cerca de 1698%.
 |
| Crescimento do Pinterest entre 2006 a 2012. Fonte: http://dstevenwhite.com/wp-content/uploads/2013/02/Pinterest-2006-to-2012.jpg |
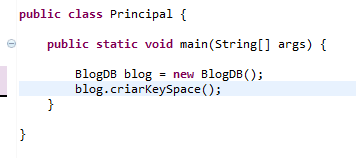
O crescimento do sistema trouxe também o aumento da complexidade de sua manutenção, já que praticamente todas as telas da interface realizam ao menos uma consulta para checar se um quadro (onde um usuário reúne publicações no Pinterest) ou um usuário já é seguido. É aí que entra o Redis.
 |
| Fonte: http://blog.pivotal.io/wp-content/uploads/2013/07/header-graphic-redis-at-pinterest-150x150.jpg |
Sempre que um usuário "A" entra no Pinterest, o Redis mantém em background vários tipos de listas que guardam informações necessárias para a melhor experiência do usuário:
- Uma lista de usuários que "A" segue;
- Uma lista de quadros (em conjunto com os usuários relacionados) que "A" segue;
- Uma lista dos seguidores de "A";
- Uma lista de pessoas que seguem os quadros de "A";
- Uma lista de quadros que "A" segue;
- Uma lista de quadros que "A" deixou de seguir, depois de seguir um novo usuário;
- Os seguidores e não seguidores de cada quadro.
Cada id de usuário é dividida em 8192 "
shards" virtuais, sendo que cada
shard roda um banco Redis. Como o Redis é do modo "
single trheaded", múltiplos bancos Redis rodam em uma só instância e múltiplas instâncias rodam numa máquina, de modo a aproveitar melhor o uso da CPU. Todas as listas rodam na memória, o Redis usa o serviço
Amazon EBS (Elastic Block Store) para salvar o log de todas operações em disco.
O motivo principal que levou os mantenedores do Pinterest a utilizarem o Redis para esse caso específico foi que o modelo tradicional previamente usado, o MySQL, estava já no limite de suas capacidades, tendo em vista o grande crescimento do número de consultas oriundo do crescimento de usuários e seus respectivos relacionamentos. O uso do Redis garantiu ao Pinterest manter qualidade e disponibilidade de seus serviços.
Referências:
Sobre o Pinterest. Disponível em <https://about.pinterest.com/pt-br>.
Acesso em 19/01/2015.
Using Redis at Pinterest for Billions of Relationships. Disponível em <http://blog.pivotal.io/pivotal/case-studies-2/using-redis-at-pinterest-for-billions-of-relationships>. Acesso em 19/01/2015.
Building a Follower Model From Scratch. Disponível em <http://engineering.pinterest.com/post/55272557617/building-a-follower-model-from-scratch>. Acesso em 19/01/2015.